
精准医疗不能只考虑基因风险

为了提供更好的个人护理和疾病预防服务,我们需要在风险评分中不仅包括遗传学信息,还需要跟踪个体不断变化的环境和健康状况的指标。
为个体提供最好的护理意味着更好地了解他们患上疾病的风险。目标是为预防性手术是否有意义,给定的药物可能有风险,或是否应该推荐某种饮食等问题,提供个性化的答案。
有关遗传风险的信息代表了提供这些答案的一种很有前景的方法。从数百万人中收集的基因组数据揭示了与糖尿病、心脏病、精神分裂症和癌症等常见疾病相关的数千种DNA序列突变。这些疾病风险的线索可以结合起来产生“多基因评分”,它提供了一个衡量个体在遗传上易患每种疾病的程度的指标。
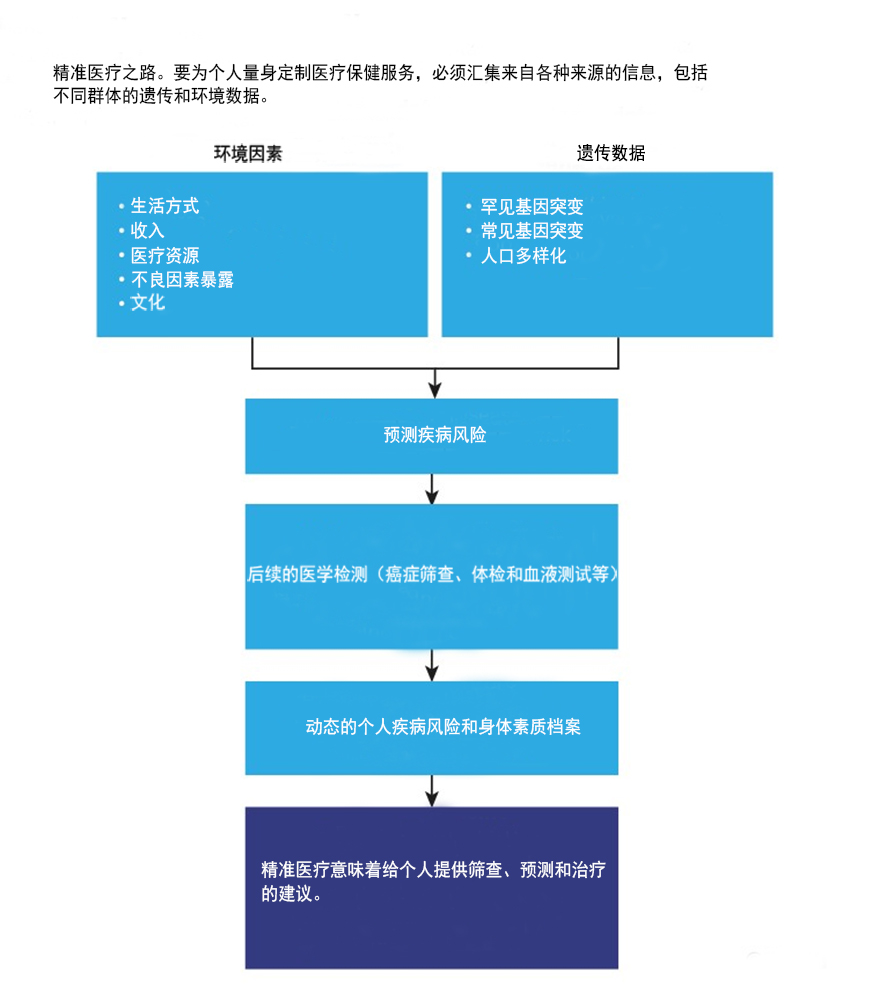
越来越多的科学家和临床医生强调这种基因分析作为个人病历不可分割的一部分的价值。其他人则认为基因分析的临床益处被大大夸大了。这场辩论往往没有认识到挑战不仅在于提高对遗传风险的理解,还在于更多地了解影响疾病风险的、相互影响的多方面因素(图“精准医疗之路”)。
在这里,我们认为临床医学必须学会开发更全面的个体风险措施,包括遗传和非遗传风险,并随着时间的推移将这些与临床数据结合起来以提供更好的护理。
有限的措施
尽管目前的多基因评分具有临床前景,但它们也有一些局限性。它们遗漏了许多相关数据来源,并且最适用于白人、富裕的人群(因为遗传研究的对象主要是这类群体)。对遗传风险的重视可能会导致忽视可能对疾病风险和进展同样重要的非遗传因素。仅基于多基因评分的风险评估也未能纳入对临床状态的实时测量,而这在与衰老相关的疾病中尤为重要。
本文的两位作者都在将人类遗传学开发成了解疾病机制的工具上进行了大力投资,并对基因分析对个性化护理的贡献充满热情。M. M.是一名内分泌学家,专注于了解2型糖尿病的遗传学,并在加利福尼亚州南旧金山的生物技术公司 Genentech 领导人类遗传研究。E.B.是欧洲分子生物学实验室(European Molecular Biology Laboratory, EMB)的副主任和英国剑桥附近的欧洲生物信息学研究所(European Bioinformatics Institute)所长,在多个基因组项目的设计和分析中发挥了举足轻重的作用。
为了更准确地评估个体健康风险(即,使药物真正个性化),研究人员和临床医生必须整合来自更广泛人群的不同类型的数据。首先,研究人员需要通过纳入更多样化的人群、对所有突变进行编目,并了解这些突变起作用的环境背景来扩大遗传风险的衡量标准。其次,研究人员和临床医生需要能够同时考虑遗传和非遗传风险因素(例如,对于2型糖尿病,这些因素将包括数百种遗传标记和饮食、运动和社会经济状况,以及当前的体检指标,如血糖水平)。最后,该领域需要摆脱将所有这些丰富的个人数据归入严格的临床类别的趋势。研究人员和临床医生不应将个人简单地归类为患有冠状动脉疾病等疾病的平均风险或高风险,而应考虑细分风险等级。与其试图将人们分为不同的疾病亚型,我们应该意识到常见疾病通常涉及多个并行运行的过程。
包容性遗传学
迟发性疾病的多基因评分主要基于大规模遗传研究中出现的常见风险变异。与导致囊性纤维化和镰状细胞性贫血等疾病的罕见的、高影响力的遗传突变相反,这些突变通常具有微妙的影响,单一突变对疾病的影响较小,多个突变具有较大的临床影响。然而,当来自成百上千个相关疾病风险突变的信息结合起来时,我们可以捕捉到疾病风险的大量个体突变。例如,在欧洲人群中,冠状动脉疾病多基因风险最高、占整个人群1%的人患该疾病的可能性至少是最低1%的人的10倍。
这些多基因评分有可能为有关筛查、生活方治疗选择的个人决策提供信息。例如,不是所有女性从45岁开始都需要每年进行乳房X线检查(如美国癌症协会(American Cancer Society)目前所推荐的那样),而是可以使用乳腺癌风险的多基因评分来调整时间表,以便对遗传风险最高的女性进行更早、更集中的筛查。
这些分数的可靠性取决于输入它们的遗传信息的准确性和包容性。目前用于构建多基因评分的大多数数据不成比例地来自近期欧洲血统的个体。然而,在一个群体中产生的分数在应用到另一个群体时通常表现不佳,例如,由欧洲个体构建的体重指数(BMI)的多基因评分在应用于较新的非洲血统的个体时失去了60%以上的预测能力。
另一个担忧是常见的遗传突变只说明了遗传风险的一部分。对于许多疾病,罕见变异也有贡献,通常比任何单一的常见突变对风险的影响更大。值得注意的例子包括基因BRCA1和 BRCA2中的罕见突变对乳腺癌和卵巢癌风险的影响,以及LDLR、APOB和PCSK9中的罕见突变对冠状动脉疾病的影响(通过这些突变对脂质水平的影响引发疾病)。不包含这些罕见的“高外显率”突变的多基因评分将为那些携带相关基因的高影响版本(或等位基因)的人提供总体遗传风险的误导性估计。同样,遗传高影响等位基因的临床后果受个体多基因背景的调节:在某些疾病中,具有有利多基因背景的高影响等位基因携带者的疾病风险等于或低于人群平均水平。
解决方案是将常见和罕见的突变整合到一个单一的遗传风险评分中。从历史上看,对等位基因频谱常见和稀有端的研究通常来自两个不同的研究群体,他们采用了不同的技术(分别是基因分型阵列和靶向测序)。然而,全基因组测序正迅速成为默认的基因检测方法。这种转变正在破除“稀有”和“常见”突变之间的人为区分,并且使同时考虑整个遗传风险范围变得更加容易。例如,这将允许乳腺癌高危等位基因携带者在筛查和预防性手术方面做出更好的决定。然而,至关重要的是,相较于常见突变,罕见突变在祖先之间的变动更大。追求公平的遗传评估将更多地取决于收集有关不同人群遗传变异和疾病风险的包容性全球数据。
全面考察
疾病风险不仅仅是遗传。对于大多数常见的迟发性疾病,个体风险在很大程度上受到非遗传因素的影响。这通常被统称为环境因素,这些因素可能包括饮食、社会经济地位、医疗保健可及性、人际关系状况和肠道微生物组多样性等各种因素。
衡量这些因素并将其整合到风险估计中并非易事。即使对于吸烟、饮食和锻炼等众所周知的因素,对疾病风险的终生影响也不能轻易地从“快照”测量中得出,例如步行的步数或过去一周消耗的估计卡路里。更重要的是,即使流行病学关联很强,也很难确定因果关系:例如,关于饮食成分(如碳水化合物和脂肪摄入量)如何影响疾病风险的辩论至今尚无定论。许多可能与疾病相关的暴露也难以重建,例如产前营养和婴儿期病原体或抗生素的暴露。
复杂的社会因素,例如获得医疗保健、教育、有效的卫生设施或住房,对个体的疾病模式有着深远的影响。与遗传风险一样,从富裕人群收集的数据可能无法很好地转化为弱势社区的疾病预测。除非科学领导者、资助者、行业和社会共同努力,重新平衡参与数据生成和临床验证的人群,否则现有的健康差异将持续存在,甚至可能被放大。
遗传和非遗传风险因素通常以难以解开的方式相互作用。例如,改变烟碱受体功能的遗传变异会影响吸烟行为,因此,与吸烟相关疾病的个体风险相关。代谢性疾病苯丙酮尿症是改变环境如何调节遗传变异后果的一个显著例子:通过采用低苯丙氨酸饮食可以减轻致病性 PAH基因遗传缺陷的破坏性后果。
临床测量值,尤其是随着时间的推移而收集的,代表了改进风险评估的另一种途径。例如,两个50岁的人,他们的多基因评分都处于2型糖尿病遗传风险的前10%。其中一个是久坐且超重,另一个则是活跃而苗条。可以合理地预期前者比后者患糖尿病的风险更大。但是现在假设十多年来,第一个人的糖化血红蛋白的年度测量值(反映一个人过去两到三个月的血糖水平)一直保持在正常范围内,第二个人的血糖水平却在稳步上升。在这种情况下,第二个人更有可能患上糖尿病。
一般来说,随着时间的推移反复收集的临床数据——来自血液检测、成像和可穿戴设备等来源——揭示了从遗传和非遗传风险因素得出的粗略预测实际上是如何在特定个体中发挥作用的,并使其成为可能绘制从健康到疾病的个人轨迹。包含实时临床数据还有助于对抗可能渗透到遗传风险解释中的宿命论。它强调了即使在那些遗传风险最高的人中,干预措施也可以减轻疾病的进展。这种综合评估也很容易被纳入临床实践。例如,胆固醇测量已经广泛用于心血管风险分层,因为它们整合了多种遗传和环境因素,以及当前临床状态的动态测量。
保持复杂性
历史上,医学一直专注于对疾病进行分类。个性化医疗通常遵循相同的路径,将人们细分为疾病亚型,或在连续测量中建立任意划分(例如高风险和低风险)。这些努力假设疾病的高度可变表现可以通过将个体分配到不同的群体来最好地解释,并且每种疾病亚型都有其自己的一组原因。然而,最常见的疾病代表了无序过程的汇合,其中一些可能在任何特定个体中起作用。例如,过早的冠状动脉疾病通常有多种不同诱因的多种混合,包括葡萄糖代谢紊乱、血脂升高、高血压和慢性炎症。精确的组合因人而异,甚至会在一个人的一生中发生变化。只有相对少数的个体(例如家族性高胆固醇血症)可以将过早疾病归因于单一原因。
当许多原因导致一个人的疾病时,跟踪所涉及的每个过程更有意义,而不是将丰富的定量信息分解为一组僵化的、通常是任意的疾病或风险类别。尽管临床决策通常需要二元决策(例如在特定时间点进行治疗或不治疗),但这些可能无法准确映射到多年前定义的类别。这些可能会成为医疗记录中“一劳永逸”的标签,为个人定义未来的医疗保健,并将注意力从疾病轨迹上的个人差异转移开。例如,一种更量化的方法会导致关于代谢综合征最合适定义的无意义辩论,或者如何最好地使用血统来定义哪些BMI阈值构成超重和肥胖。
跟踪多个测量结果可以揭示每个人在健康和疾病方面的状态的变化。然后,当有必要做出是与否的临床决策时,如是否手术,或是否尝试药物A或 B,个人和医生都可以依赖更丰富、最新的信息,而非以来数年前定义的分类。
展望
我们该怎么做?研究人员应该致力于在他们的工作中采用更全面的观点。研究人员、资助者和行业需要在研究的设计和实施中接受更大的多样性,不仅要关注性别和种族,还要关注影响疾病风险和获得医疗保健机会的社会、文化和经济因素。主要资助者最近鼓励更多样化地参与人口队列和生物库的举措是受欢迎的,但将现代人口的多样性减少到人口普查定义的类别并不能公平地对待如此多复杂、混合的血统。
仅基于风险因素预测来建立个性化医疗的努力将是徒劳的。参与这项工作的所有人——研究人员、行业、资助者、政府和公民——都需要齐心协力,收集大量、丰富的数据集,这些数据集超越了静态的一次性测量,可以捕捉个人健康轨迹。然而,除非以标准化格式收集数据并以允许合并和比较来自不同研究和人群的信息的方式共享数据,否则这些努力注定会失败。这将不可避免地将研究和临床护理领域结合在一起,并将要求我们解决有关数据所有权、隐私、访问平等、公平和社会责任的基本问题。制定此类标准的全球努力已经到位,例如全球基因组学与健康联盟(Global Alliance for Genomics and Health)。
实现这种更全面的评估需要时间和努力。但由此产生的对疾病和个人风险的理解将更深入、更广泛、更有能力将个性化医疗融入常规医疗保健。
原文检索:
Mark McCarthy & Ewan Birney. (2021) Personalized profiles for disease risk must capture all facets of health. Nature, 597: 175-177.
张洁/编译



{kind=link}