
生物样本库加速了基因-病理表型的发现

对患有特定疾病或属于特定族裔群体人群的生物样本进行测序,可以提高对遗传变异如何影响常见疾病的认识,从而有助于疾病的预防、诊断和治疗。
牛津大学(University of Oxford)纳菲尔德人口健康系流行病学家、英国生物样本库首席科学家Naomi Allen认为,生物样本库对于了解遗传因素如何与疾病症状相联系至关重要。通过将样本与个人的电子病历链接起来,并对他们进行长期跟踪,可以将基因图谱与他们一生的健康状况相关联。
全世界有120多个生物样本库,并在过去30年中不断发展。它们的范围囊括以大学为主的小型样本库,以及政府支持的大型样本库。除了收集和储存样本外,它们还为个性化医学研究提供临床、病理、分子和放射学信息。
生物样本库够通过帮助研究人员将基因型与表型联系起来,从而探索疾病的病因。这是一个通过全基因组关联研究(genome-wide association studies, GWAS)已经进行了多年的过程,但事实证明它远非简单易行。纽约西奈山伊坎医学院(Icahn School of Medicine)的转化遗传学家Judy Cho表示,在过去15到20年间从GWAS获悉,基因组存在许多变异,它们的作用范围很小,即使将整个基因组中的大多数常见变异加在一起,它们也只占表型变异的一小部分。
目前生物样本库正在加速发展。它们使研究人员可以轻松地分析越来越多的生物样本和相关的临床数据,以表征疾病机制、找到新的药物靶点并确定最有可能从特定治疗方法中受益的患者。田纳西州范德堡大学医学中心(Vanderbilt University Medical Center)的临床药理学家兼BioVU生物样本库主任Dan Roden表示,将基因组信息嵌入电子医疗记录,随后在生命进程中使用它,这是一个很有吸引力的愿景。但这也是一个很难实现的目标,在创建这样的基础设施时有很多管理问题。BioVU实现这一愿景的步骤是存储从废弃血液中提取的DNA,在常规临床检测过程中收集,与去标识化的医疗记录相连。现在约有25万份DNA样本可供范德堡大学的调查人员使用。
但是,壮大队列并不是唯一的解决方案,对常见疾病的深入理解还可以通过分析小型疾病和/或特定种族人群来发现,因为这些人群浓缩了重要的基因组信号。遗传技术的进步以及致力于在生物样本库中捕获遗传的多样性,正在帮助研究人员以具有成本效益的方式建立牢固的基因-病理表型关联(见“生物样本库与基因/病理表型之间的联系”)。
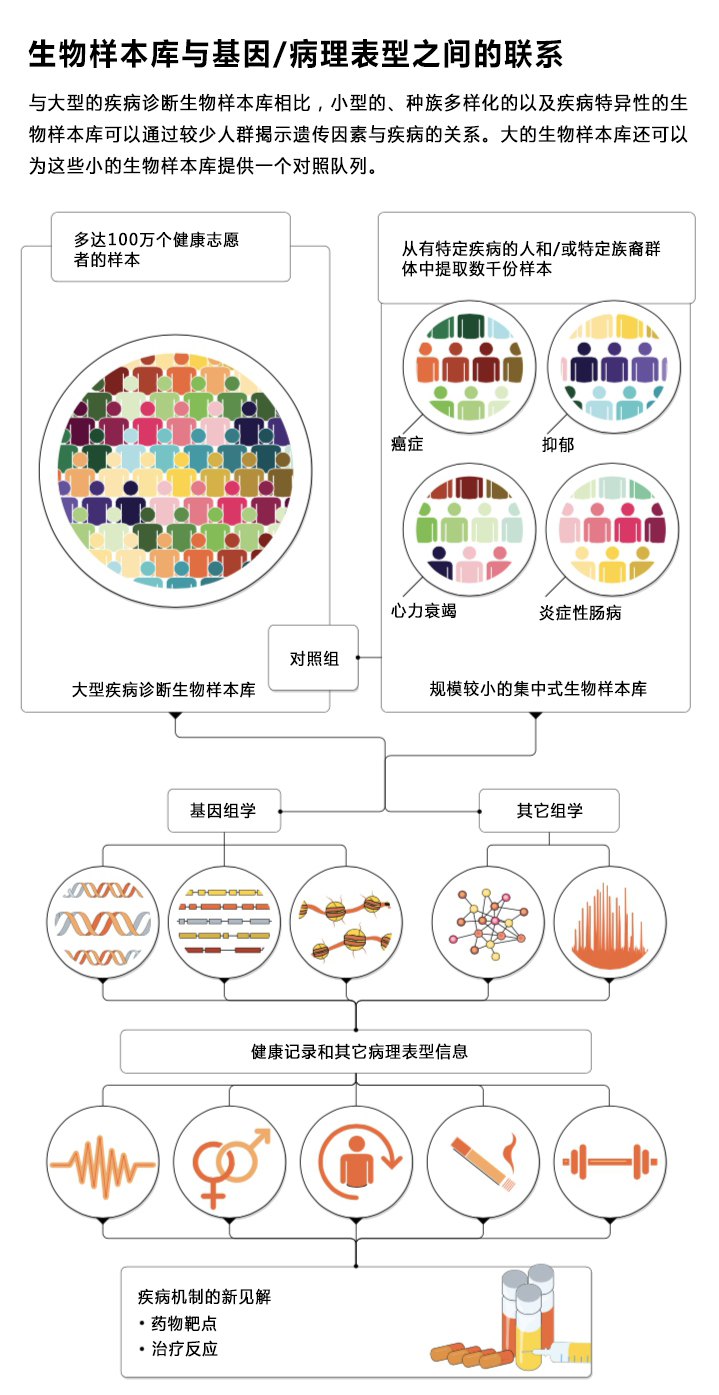
改进生物样本库
英国生物样本库是世界上最大的生物库之一,存储了2006年至2010年招募的50万人的样本,链接一系列电子健康记录。2019年,它获得了对所有样本进行高覆盖(X30)全基因组测序的资金,首批20万个样本测序结果将于2021年获得。Allen表示,因为需要众多样本量才能看到小的遗传效应,许多研究不得不将不同数据库的数据拼凑在一起。英国生物样本库的好处是,它提供了标准化、高质量的50万人集中在一个数据集的基因和健康状况数据。
来自英国生物样本库的样本帮助确定了COVID-19的遗传和社会人口学风险因素,并有助于确定免疫系统的基因变异,这可能有利于预测住院患者的疾病结局。
然而,大规模生物样本库也有其缺点。志愿者往往比全国平均水平更健康、更富有,并不能代表人口的多样性。在英国生物样本库中,95 %的样本来自于白人。Allen表示,这不是一个特别好的研究种族差异的队列。有必要在黑人和少数族裔群体中进行补充研究,以比较遗传差异以及它们如何影响健康状况。
Cho是美国国立糖尿病、消化及肾脏疾病研究所(National Institute of Diabetes and Digestive and Kidney Diseases, NIDDK)遗传学联盟的成员,致力于明确非洲裔美国人和阿什肯纳齐犹太人对炎症性肠病(inflammatory bowel disease, IBD)易感性的遗传因素。Cho表示,目前的遗传风险评分不能很好地预测不同人群,进一步了解遗传多样性将具有真正的启发性。
为了提高多样性,生物样本库正在引进不那么具有代表性的人群。Cho还管理着拥有5万多个样本的BioMe生物样本库,她表示正在优先增加来自非洲裔美国人的样本。出于社会正义原因这样做是正确的,出于科学原因这也是正确的。
实现人人享有精准医疗
哈佛大学医学院(Harvard Medical School)擅长遗传学的精神病流行病学家Erin Dunn表示,生物样本库的多样化也是一种很好的让少数群体参与健康研究的方式。如果不将所有人群纳入遗传学研究,就缺乏对一个人群的遗传变异是否以及如何扩散到另一个人群的了解。
Dunn等人利用西班牙裔社区健康研究/拉美裔研究(Hispanic Community Health Study/Study of Latinos)的数据,对西班牙裔/拉美裔的抑郁症状患者进行了迄今为止规模最大的GWAS。他们发现了与抑郁症状相关的不同遗传变异,这些变异与欧洲血统的人的研究中报告的遗传变异不同。Dunn表示,这是一个开始,但仍有很多工作要做,以拼凑出遗传变异中相似和不同的方面。
与宾夕法尼亚大学(Penn University)的研究人员合作,Cho还发现不同祖先的人之间的遗传差异对健康的影响。他们使用Illumina的全球测序阵列筛选了9000多名来自Penn Medicine或BioMe生物库的非洲人和拉丁裔,他们发现转甲状腺素蛋白基因(transthyretin, TTR)的变异与可治疗的心力衰竭之间存在显着关联。这些发现表明,TTR测试可以识别这些族裔群体中的高危人群从而进行早期诊断,重要的是可以进行早期治疗。
评估选择性遗传变异的一种具有成本效益的方法是使用生物样本库数据作为“对照”组,并使用经过类似遗传分析的样本做汇总分析。据Allen解释,研究人员经常使用英国生物样本库数据作为一般人群对照组,与自己的“病例”患者队列进行比较。
随着生物样本库中持有的数据量增加到PB(petabyte,1 PB = 1024 TB)级(主要是由基因组学驱动),数据下载模式将变得难以维持。一些生物样本库正在开发基于云的平台,以减少对计算机资源的需求。Allen表示,他们希望实现数据访问的民主化,特别是针对中低收入国家,这样世界上任何研究人员都可以使用这些数据。
第一个实施云端模式的大型生物库是美国“All of Us”计划,该计划正在开发一个由100万名不同祖先的参与者组成的队列。All of Us数据和研究中心的联合主任Roden表示,All of Us数据集现在包括25万名受试者,他们的数据通过研究员工作台(Researcher Workbench)提供给研究人员。
使用表征良好的样本为GWAS提供动力
由于大型生物样本库并不特殊招募患有某些疾病的人,因此对于疾病的GWAS分析来说,研究人员往往缺乏动力。识别显著基因型-病理表型关联的一种方法是使用具有特定特征的小队列。现在英国Breast Cancer Now抗乳腺癌慈善机构(Breast Cancer Now unit)的非临床代表,也是伦敦国王学院(King’s College)的癌症生物信息学家Anita Grigoriadis表示,通过分析来自患有特定疾病、接受过相同类型手术或对药物有类似反应的患者的样本,可以减少混杂因素的数量,并增加重要发现的可能性。
Grigoriadis的团队正在研究三阴性乳腺癌患者的生物学特征,以确定有鉴别性的特征,并指导靶向治疗的发展。他们使用盖伊和圣托马斯医院(Guy’s and St Thomas’ Hospital)的乳腺癌生物样本库。该生物库自20世纪70年代以来一直在收集患者的肿瘤、血液和其它组织样本。Grigoriadis表示,她们能够通过探索丰富的三阴性乳腺癌生物样本库资源,并提供大量的长期临床和病理随访信息,为高危乳腺癌患者群体确定潜在的药物靶点和生物标志物。
进一步推进基因型和病理表型的关联将遗传变异与疾病联系起来只是第一步。Dunn表示,一旦确定了这些基因变异,就可以开始确定它们是否真的是因果关系,以及它们可能与哪些类型的生物过程有关。
为了弄清遗传因素的作用,研究人员正在分析基因表达模式(转录组学)及其调控方式(表观遗传学)。进一步了解这些基因编码的蛋白质(蛋白质组学)及其活性(代谢组学)将有助于将复杂的疾病过程以及生活经历和环境因素的影响结合在一起。Allen指出,深入研究个体的蛋白质组学和代谢组学谱可能会告诉我们很多有关饮食等因素如何影响健康的机制。
这些多组学分析有助于剖析疾病背后的信息流。Cho表示,多组学可以帮助我们了解每一步将基因型转化为病理表型的过程。她还强调了进行单细胞测序(single cell sequencing,sc-Seq)的重要性,以测量单细胞的转录组范围的基因表达。这样的分析对于确定致病变异介导的细胞类型和状态至关重要,并可能引导出为患者定制的疗法。据Cho补充,使用sc-Seq,她们在克罗恩病(Crohn’s disease)患者中发现了一个难治性特征,这将有助于确定患者是否会对抗TNF治疗做出反应。
由于生物样本库的扩大,捕捉到了人口和相关数据类型的多样性;技术的进步使得能够对数据进行详细和有力的分析,研究任何常见疾病或性状背后的遗传学正在成为可能。通过将全基因组测序和深层表型分析纳入临床评估,许多目前诊断不足的疾病可以实现预防,或更早、更有效地进行治疗。
Roden表示,该领域正在从发现阶段慢慢转向实施阶段。但是将以合理的成本产生的大量信息转化为常规医疗保健的过程并不容易。
但这是Roden和其他人热衷于应对的挑战。毫无疑问,提供可行的结果将使预防和治疗策略得到优化。Cho认为,即使是很小的步骤,也能给患者的生活带来很大的改变。
原文检索:https://www.nature.com/articles/d42473-020-00238-1
郭庭玥/编译



{kind=link}